From Challenges to Solutions

From Challenges to Solutions
This 5-minute read provides a comprehensive breakdown of the costs involved in building an enterprise-level RetrievalAugmented Generation (RAG) system.
I ll explain the necessity of such a system to overcome the limitations of Large Language Models (LLMs) in handling complex tasks that can be a perpetual headache.
The aim of this paper is to consider and measure the full cost, and technical considerations, of implementing such a system from scratch.
Large Language Models (LLMs)
While LLMs demonstrate remarkable capabilities in general knowledge, reasoning, and coding, they are not directly applicable for enterprise-level professional tasks for several key reasons:
Legacy Data and Hallucinations:
LLMs are trained on outdated data, which can include conflicting or incorrect information, leading to potential inaccuracies.
Limited Functionality:
Web-based chatbots excel in simple Q&A scenarios but fall short in handling complex tasks.
Data Integration Needs:
Enterprises require LLMs to process vast amounts of both public and internal documents for professional applications.
To bridge these gaps, a Retrieval-Augmented Generation (RAG) system is necessary. This system connects data with LLMs, enhancing their utility.
While basic RAG systems can be created by simply dropping a PDF into ChatGPT and asking questions, scaling to handle large volumes of data is exponentially more complex and costly.
A common misconception is that LLM costs dominate the expenses of a RAG system. This paper aims to break down the essential components of a RAG system and elucidate the costs involved in building it, even before the first interaction occurs.
Components of an enterprise level RAG
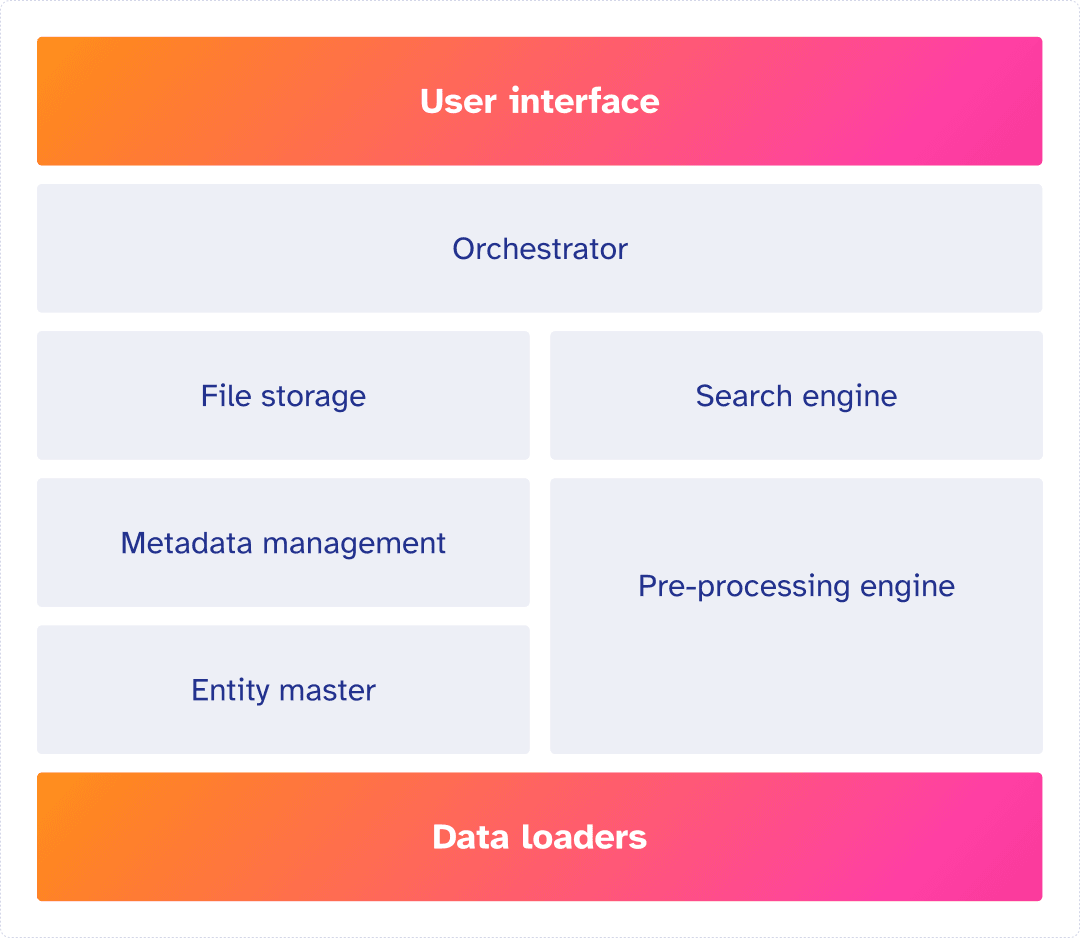
Data Loaders
Efficiently import and process data from various sources, crucial for handling large volumes of documents. Ensures data is ingested promptly and accurately, impacting the quality and timeliness of responses.
Web Scrappers:
Extract relevant data from web pages, allowing real-time updates and comprehensive data collection. This enhances the breadth of information available, improving response accuracy and relevance.
Connectors to 3rd Party Applications/Databases:
Enable seamless data exchange with external systems and databases, ensuring that the system has access to the latest data. This integration is vital for maintaining up-to-date and accurate responses.
Entity Master
Centralised repository for all entities, ensuring consistency and accuracy across the system. This helps in precise entity recognition, improving the system s understanding and contextual relevance.
Entity Metadata Maintenance and Updates:
Regular updates and management of entity-related metadata ensure that the system s knowledge base is current. This impacts the reliability and correctness of the information provided.
Metadata Management
Handles document and data metadata to enhance search and retrieval. Efficient metadata management facilitates faster and more accurate information retrieval, improving overall response quality.
Pre processing Engine
Prepares data by cleaning, normalising, and transforming it, which is essential for handling large data volumes. Proper pre-processing ensures that the data is in a usable format, enhancing the system's performance and accuracy.
PDF Parsing:
Extracts text and metadata from PDF documents, allowing the system to process and understand information contained in PDFs. This capability is crucial for accessing a wide range of document types.
Embedding:
Converts data into vectors for efficient retrieval and analysis, allowing the system to handle large datasets quickly. Embeddings improve the system s ability to find relevant information and provide accurate responses.
File Storage
Secure storage for PDFs and flat files ensures that all documents are easily accessible and protected. Proper storage solutions enhance data retrieval speeds and ensure data integrity.
Search Engine
Advanced search capabilities for quick and accurate data retrieval, crucial for managing large document volumes. A robust search engine improves the system's ability to find and deliver relevant information swiftly.
Orchestrator
Manages and coordinates workflows and processing logic, ensuring efficient operation. This component is vital for maintaining system performance and reliability.
Connect to LLMs:
Integrates with large language models to enhance data processing and response generation, leveraging advanced AI capabilities for improved understanding and generation of responses.
Processing Logic Development:
Customisable logic for specific data processing needs, allowing the system to handle complex queries and data scenarios effectively.
Workflows:
Streamlined processes to ensure efficient data handling and response generation. Well-designed workflows enhance system efficiency and the quality of outputs.
User Interface
Intuitive interface for users to interact with the system, ensuring ease of use and accessibility. A user-friendly interface improves user engagement and satisfaction.
Visualisations:
Graphical representation of data and insights for easy understanding and analysis. Visualisations help users quickly grasp complex information, enhancing the overall user experience.
Operating Costs
Let's firstly look at how much it cost to run the system without considering development cost yet. To simplify the calculations, the costs are based on 1 million pages worth of PDFs (10,000 PDFs, each with 100 pages). Some costs are one off calculations, some costs are for storage, so let's calculate how much every year the cost will be.
For simplicity, I have used standard cloud provider's pricing for comparison purposes.
PDF Parsing
PDFs should be parsed into granular blocks for later retrieval which is much more accurate. We will use Microsoft's document AI parsing service, which is the best quality commercial APIs based on our experience.
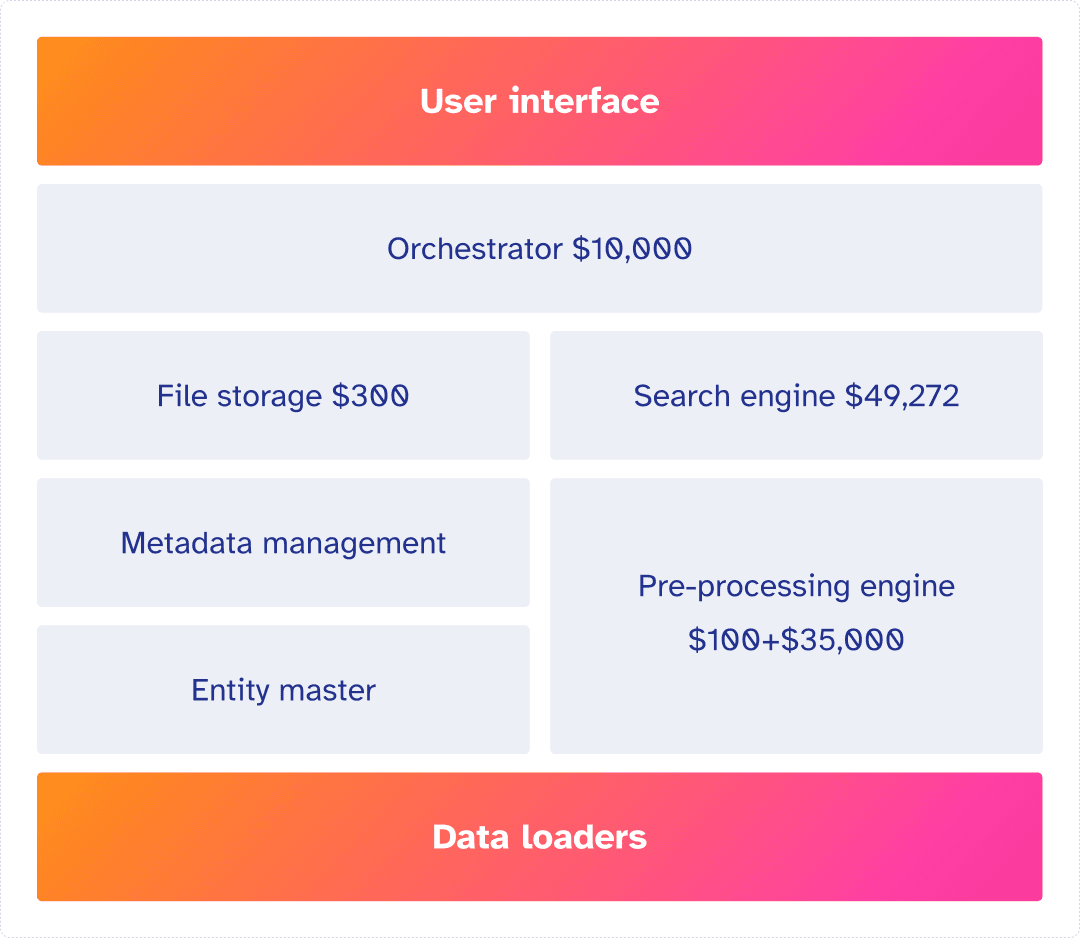
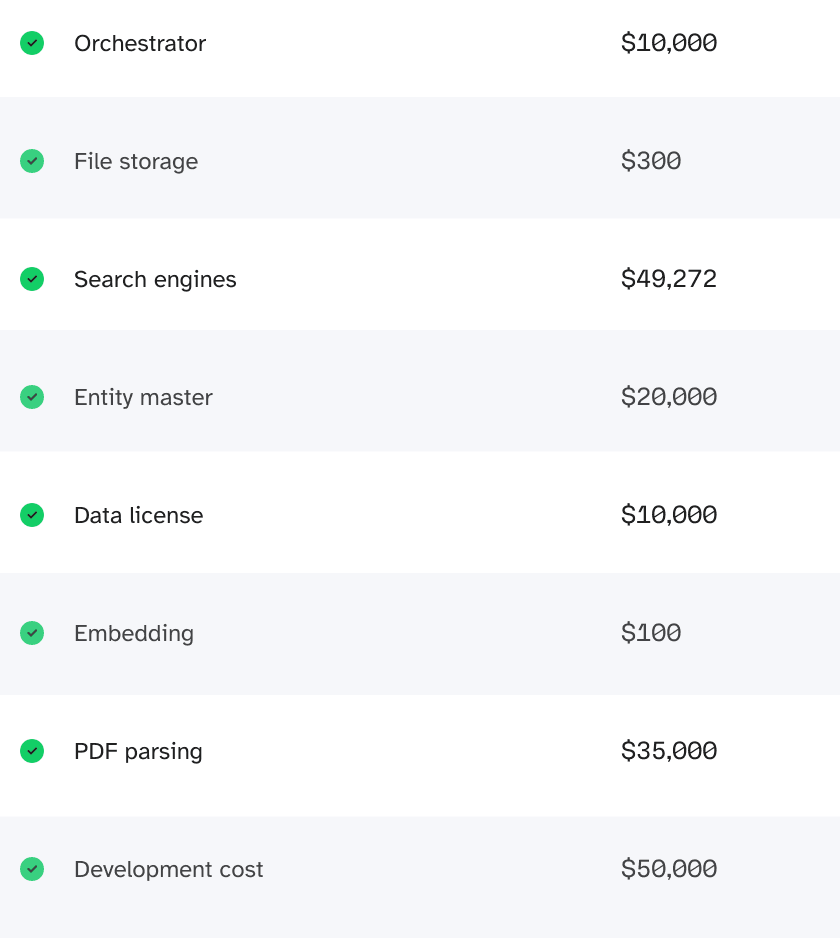
The cost of PDF parsing is about $35 per 1000 pages,
so in total, $35*(1,000,000/1000) = $35,000
Link : https://azure.microsoft.com/en-gb/pricing/details/ai-document-intelligence/#pricing
Embedding
OpenAI s Ada v2 is a mainstream embedding model, and its price is $0.10 / 1M tokens
Assuming about 1000 tokens per page, so in total
1,000,000 pages / 1,000 tokens per page * $0.1 = $100
File Storage
The file size grows significantly when converted to vector format, especially at block level. If we assume each page is 1MB and AWS storage starts from $25 per month. To store data for 1 year will cost 1T*$25*12 = $300
Search Engine
To keep it robust, we use Elastic 1.7 TB storage | 58 GB RAM | 8 vCPU and 2 zone configurations, which is $5.6246 per hour, so total cost in one year is:
$5.6246 24*365 = $49,272
Orchestrator
Let's add up all the general costs for application deployment, databases, etc, every year it costs $10,000.
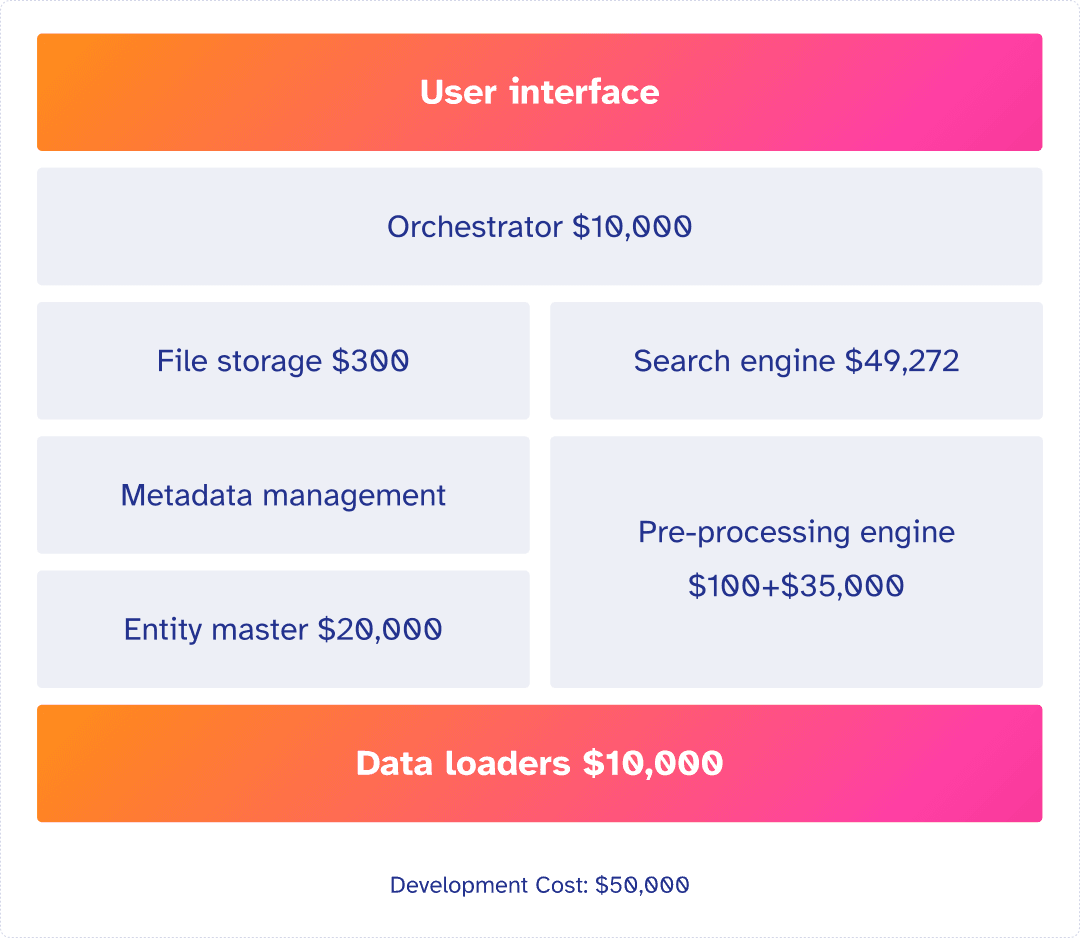
In total, the operating costs are:
$10,000+$300+$49,272+$100+$35,000 = $94,672
Total Costs
In total to process 1 million pages of PDFs, it costs
data+licensing+processing = $94,672+$10,000+$20,000 = $124,672 And Development cost of $50,000
Total Estimated Cost = $174,672*
*This can be considered an on-going cost, however, the actual figure will vary on the number of pages PDF you run through the RAG system.
Hidden Costs
Developing a robust Retrieval-Augmented Generation (RAG) system is far more complex and expensive than it initially appears. While a simplistic estimation might suggest 100 development days and $50,000, this overlooks several hidden costs that can escalate unpredictably:
Scalability Challenges:
As data volume increases, the system architecture may need significant changes to handle the load efficiently.
Functionality Enhancements:
Adding new features and supporting diverse use cases and clients requires continuous development and integration.
Performance Optimisation:
Ensuring the system runs smoothly under heavy use demands ongoing performance tuning and resource allocation.
Comprehensive Testing:
Extensive testing is necessary to ensure reliability, security, and accuracy, which can be time-consuming and costly.
Maintenance and Updates:
Regular maintenance and updates are essential to address emerging issues and keep the system current with technological advancements.
These factors can drive the development costs into millions, with substantial risks of cost overruns and project delays. Given these complexities, partnering with a provider offering sophisticated RAG solutions is often a more prudent and cost effective choice. Such providers bring proven expertise, scalable architectures, and comprehensive support, mitigating risks and ensuring a more reliable outcome.
In Summary
You may think this is quite expensive and you won't need to process a million pages of documents. But this is exactly the scenario many of our investment research, risk and compliance clients need to deal with.
At Orbit, only 1 year's worth of global filings data is about 80 million pages, and we have been working on this for 10 years at that scale so you can see how it can rack up quickly.
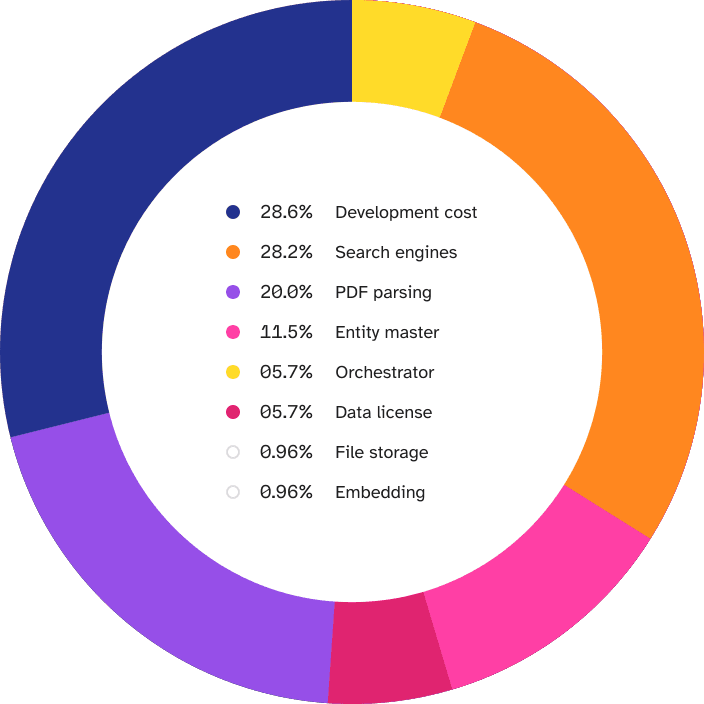
Appendix: Data
Cost Breakdown